最近看了原网易游戏引擎架构师蔡能老师一些游戏相关的文章,其中有提到在游戏中常用的脚本语言lua和C/C++之间相互调用。lua在游戏中有很多运用,耳熟能言的有《魔兽世界》,魔兽中UI和很多插件都是用lua来写。在服务端也有很多运用,nginx有支持lua语言的模块,具体可以看一下openresty这款阿里改写nginx服务器,它集成nginx lua模块,书籍可以翻阅《OpenResty-Best-Practices》。
嵌入lua脚本
在C\C++里面调用lua脚本通常有二种做法:一是读取后直接运行,调用luaL_dofile函数;还有一种方式是用luaL_loadfile函数将脚本压到栈顶,手动调用pcall运行脚本。
下面图片给出了lua堆栈的示意图,方面我们理解下面的代码。
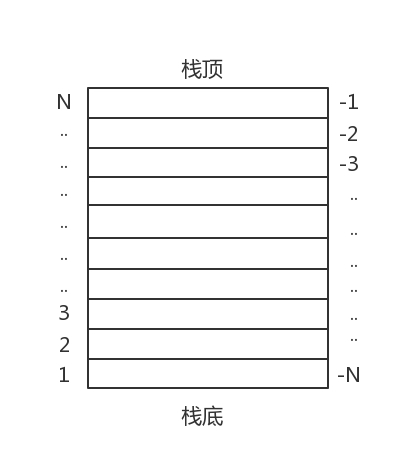
Lua调用C函数
有时候我们会把需要运行效率的模块用C/C++来使用,然后封装以后交给lua来调用。这时候我们要用lua_register将函数注册到lua虚拟机里面,然后我们就可以在lua脚本里面调用这个函数了。lua_register是一个宏函数,如下:
#define lua_register(L,n,f) (lua_pushcfunction(L, (f)), lua_setglobal(L, (n)))
第1个参数L是虚拟机指针,第2个参数是注册到虚拟中的函数名称,第3个参数是一个函数指针,格式为”int ()(lua_State*)” .下面我们来看一下具体的实现。
代码实现
这些代码能运行的前提是你的电脑已经安装了lua,具体如果安装lua请自行搜索一下。
main.cpp代码
#include <iostream>
extern "C" {
#include <lua.h>
#include <lualib.h>
#include <lauxlib.h>
}
//lua_register函数的第3个参数需要的是int ()(lua_State*)类型的函数指针
int c_sum(lua_State* l)
{
long long result;
const long long num1 = lua_tointeger(l, 1);
const long long num2 = lua_tointeger(l, 2);
result = num1 + num2;
std::cout<< num1 << "+" << num2 << "=" << result << std::endl;
lua_pushinteger(l, result);
return 1;
}
int main(int argc, char **argv) {
int r;
const char* err;
lua_State* ls;
ls = luaL_newstate();
luaL_openlibs(ls);
//注册c_sum函数到lua虚拟机,名称改为my_sum
lua_register(ls, "my_sum", &c_sum);
//加载lua脚本
r = luaL_loadfile(ls, argv[1]);
if (r) {
err = lua_tostring(ls, -1);
std::cout<< "lua err1: " << err << std::endl;
return 1;
}
//运行lua脚本
r = lua_pcall(ls, 0, 0, 0);
if (r) {
err = lua_tostring(ls, -1);
if (err) {
std::cout << "lua err2: " << err << std::endl;
}
return 2;
}
lua_close(ls);
return 0;
}
测试脚本test.lua脚本
print("test lua running")
result=my_sum(5,8)
print("sum result: " .. result)
编译脚本,然后运行程序,将脚本名称作为第一个参数传入。结果如下:
#./use_lua test.lua
test lua running
5+8=13
sum result: 13
这里我提供一下我代码的示例,我用ide用的是clion。源码下载,use_lua.tar。
近期评论